Depositing Data¶
Adding single objects¶
Adding objects to an existing collection, or sub-collection, is done from the display page for that collection. You can navigate to the collection through the ‘My Collections’ link found in your workspace (Fig. 25 (1)).
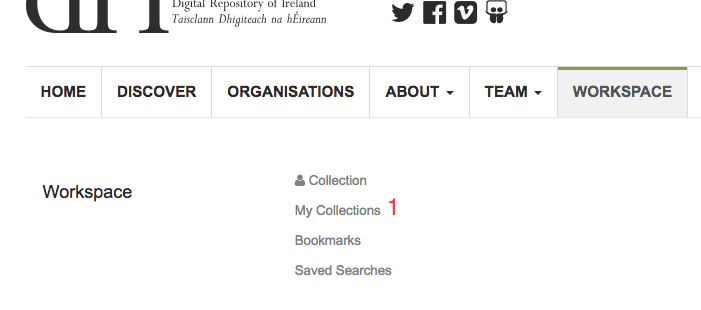
Fig. 25 My Collections workspace link¶
On the right hand side of the collection display page you should see the editor tools menu (Fig. 26 (1)). There are two options for adding objects: Add an Object (Fig. 26 (2)) and Upload Object XML (Fig. 26 (3)). If you have an existing XML metadata file in one of the supported standards then the fastest option is to choose to upload this to the Repository. If not, you can create the object’s metadata using the object creation form.
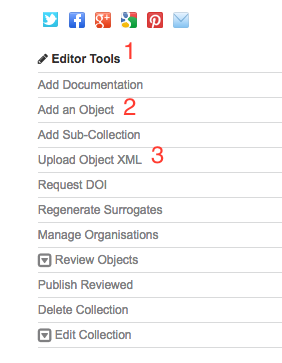
Fig. 26 Collection editor tools¶
The form for creating an object is very similar to that described for creating a collection. You can get more information on the fields and how they should be completed in DRI’s metadata guidelines.
Choosing to upload XML will direct you to the file uploader (Fig. 27 (1)). Clicking on the ‘Upload Metadata file’ (Fig. 27 (2)) box will open a file chooser dialog from which you can pick the XML file to upload. Once a file has been selected, pressing continue will upload the file and create the object. If successful you will be redirected to the new object’s display page.
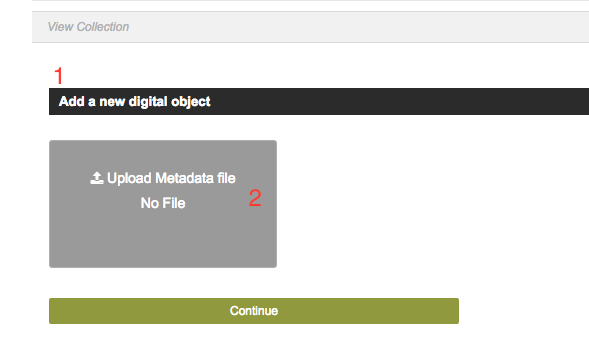
Fig. 27 Upload XML metadata¶
Adding assets to an object¶
Assets refer to the data that an object’s metadata describes, such as image, audio, or video files. From the object’s display page you will have access to the object tools menu. Selecting ‘Upload Asset’ (Fig. 28 (1)) will open a file chooser from which you can select the file to upload.
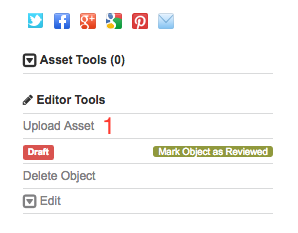
Fig. 28 Upload asset¶
Once selected you should now see an ‘upload’ (Fig. 29 (1)) button to the right of the menu option. Pressing this will upload the file and attach it to the object.
Fig. 29 Upload asset button¶
Once uploaded a message indicating if the upload was successful will be displayed. The Repository will now process the uploaded file for display. For example, in the case of an image, a thumbnail and several other web-friendly images of various sizes will be created. This is carried out by a pipeline of background processes (Fig. 30). Until these are completed a temporary message will be shown in the asset display.
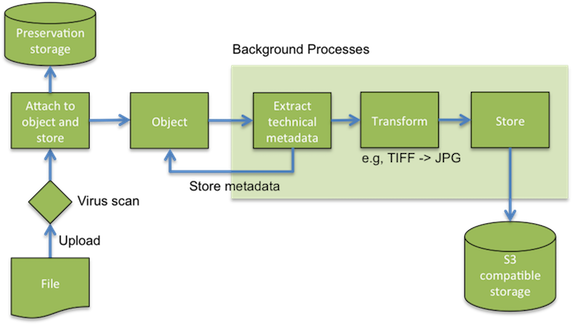
Fig. 30 Asset upload processing pipeline¶
To check on the progress of these processes you can select View Assets (Fig. 31 (1)) in the Asset Tools menu.
Fig. 31 Asset tools menu¶
This page list all the assets currently attached to the object. Here you can see the current processing status of the asset (Fig. 32 (1)). To get more information you can view the asset details (Fig. 32 (2)). You can also delete the asset (Fig. 32 (3)).
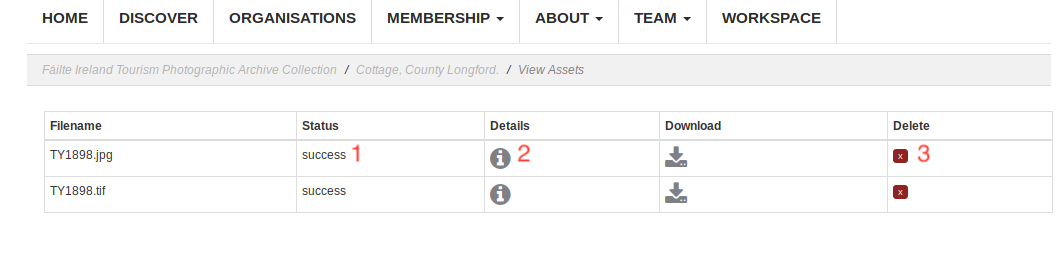
Fig. 32 View Assets¶
On the asset details page (Fig. 33) you can view the metadata automatically extracted from the uploaded file (Fig. 33 (1)). You can also see the progress and status of the background processes (Fig. 33 (2)). This will show if the task has succeeded or in the case of a failure will show the error. You can also choose to replace the asset with a different file (Fig. 33 (3)).
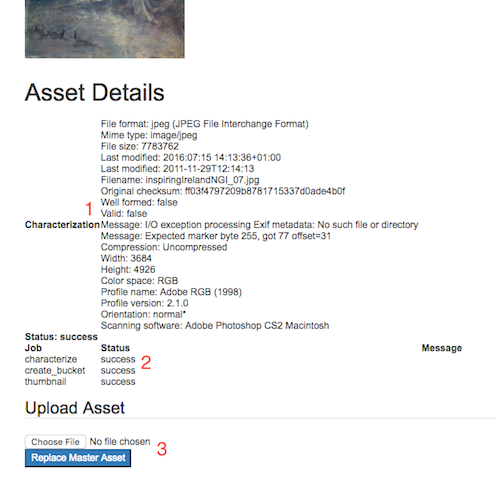
Fig. 33 Asset details¶
Adding multiple objects¶
If you have multiple pre-existing metadata records it is also possible to add these as a batch into a collection. To do this it is necessary to arrange the metadata and any data files into a defined folder structure(Fig. 34). Metadata records should be contained in one folder with data in another separate folder.
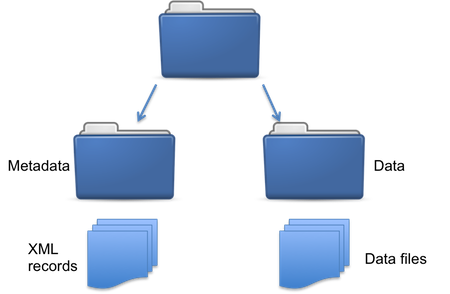
Fig. 34 Folder structure¶
Data files are matched to their metadata record by filename, e.g., object_1.jpg will be attached to object_1.xml. It is possible to connect multiple data files with a single metadata record by appending an increasing count to the data filenames, e.g., object_1_1.jpg, object_1_2.jpg would both be associated with object_1.xml. The display order of files added in this way will match the count, i.e., _1.jpg will display first, _2.jpg second, and so on.
If the order of the data files is not important, or the filenames need to be preserved, the files can instead be added to a folder with the same name as the object’s metadata file. So for the structure shown above where the metadata is stored in Metadata/object_1.xml, files can be placed in Data/object_1/, e.g., Data/object_1/afile.jpg, Data/object_1/someotherfile.tif. All the files found in this folder will be attached to the object. The display order of the data files can not be determined or modified later.
The next step is to make the data available to the Repository by copying it to a staging area through the DRI hosted Nextcloud server, that can be found at https://repository.dri.ie/cloud. In Nextcloud create the same folder structure as described above and upload the metadata records and data files.
A wizard (Fig. 35) that guides you through ingesting the data can be found by following the ‘New batch ingest’ link in your repository workspace.
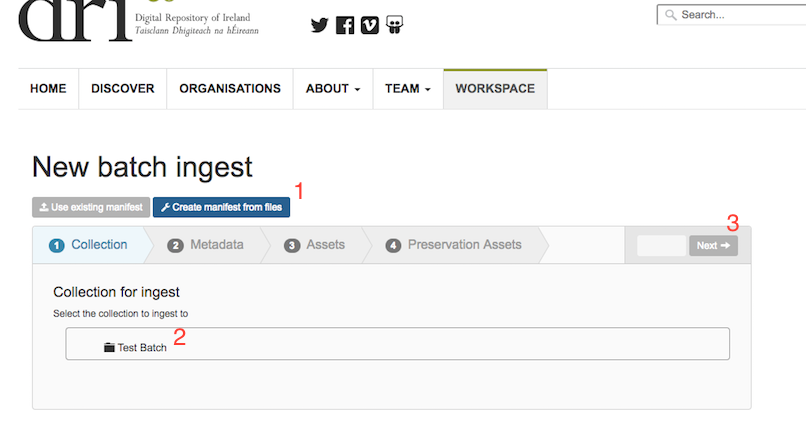
Fig. 35 Batch ingest wizard¶
Pressing ‘Create manifest from files’ will start the process (Fig. 35 (1)). First, you must select the collection that the data will be added to (Fig. 35 (2)). This must be created in advance. Pressing ‘Next’ (Fig. 35 (3)) will move to the next step. Here you will see the folders that were created in Nextcloud. Select the folder containing the metadata, press ‘Next’, and select the folder containing the data files. The next step allows you to optionally select a folder containing preservation data files. These are files that should be attached to metadata records (through matching filenames as before) but not displayed to users, or processed by the background tasks. Pressing ‘Complete’ will start the ingest and bring you to the ingest status page (Fig. 36).
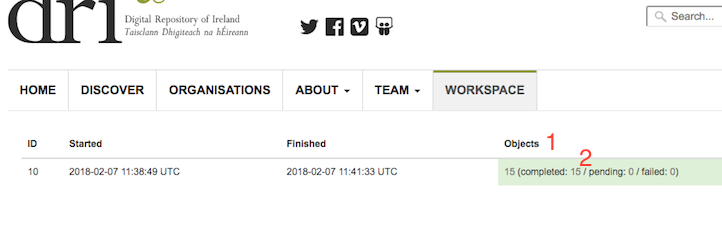
Fig. 36 Batch ingest status¶
From the status page you can see the total number of objects that will be ingested (Fig. 36 (1)), as well as the current number completed. Status information for each object can be seen by following the status count links (Fig. 36 (2)).